Last week, I overheard a conversation that caught my attention. Someone was trying to explain where to locate business data within the organisation’s systems (not Tape). My immediate thought was that this process would have been much simpler if the data were organised in Tape. Then it struck me—it would be even better if you could just ask the system directly and receive relevant responses.
I’ve developed several integrations between AI and Tape—things like drafting replies, flagging important emails, generating lists of interesting posts, categorising emails, webpages, and documents, and building full project management systems that can generate deliverables and create outlines of actions based on basic project descriptions. I’ve even built basic virtual assistants that generate tasks or contact notes depending on the content of a message. However, all of these are quite basic; they rely on the context I provide, and much of the logic is built directly into Tape. What I wanted was something smarter—not just something with a bit of context, but a system that truly understood my data and could respond with complete answers about anything I needed, from anywhere in my system, as long as I’d made that data available.
IMPORTANT:
It is absolutely essential that you understand exactly what data you’re making available to the AI, and just as importantly, who you’re granting access to the virtual assistant (VA). I cannot emphasise this enough. If you provide the VA with access to information in a locked workspace, but then make the VA available to people who don’t have permission to access that workspace, they could ask the VA a question and it would respond with all the data it has, regardless of whether the person should have access to that information or not!
Now we have that out of the way here is a short video showing it in action:

My second warning is that this really pushes the limits of what we consider ‘Low Code’. I’ll do my best to explain the process, but I likely won’t dive too deeply into the technical details. Feel free to ask if you have questions about any specific parts. The aim of this post is more to demonstrate what’s possible with Tape, rather than provide a step-by-step guide.
The first step is to make sure the data we want the AI to access is available in a format it can work with:
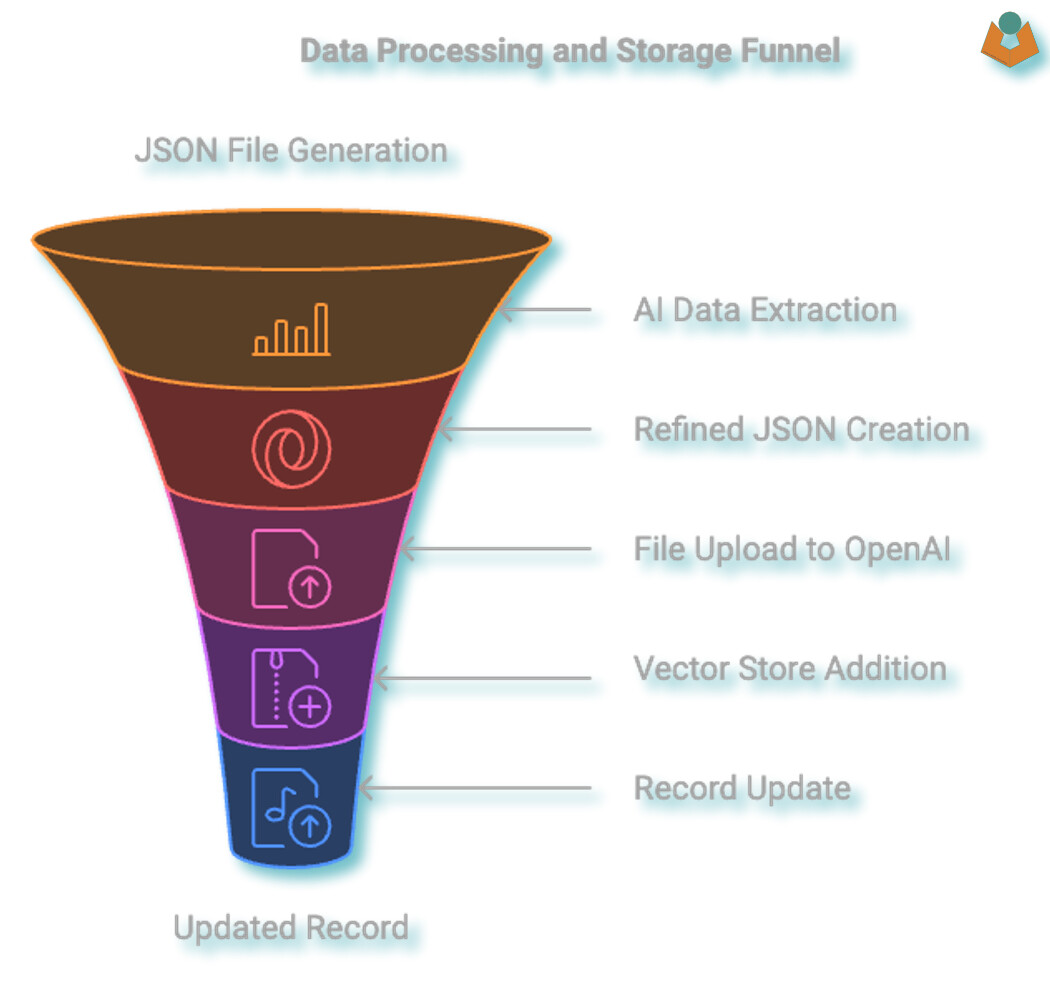
We are going to do this via a JSON file. Tape is nice to us here, if you run:
const details = await tape.Record.get(current_record_id);
details now contains all the information within the record, including the IDs of related records. However, it also includes a lot of duplication and data that isn’t relevant for our current purpose. While we could use something like JSONata to restructure the data into a more efficient JSON format, I’d prefer not to write custom code for each app I want to run this on. Instead, we’ll use a ‘dumb’ AI approach by passing the bloated (for our needs) JSON to the AI and asking it to simplify and return a cleaned-up version. The reason we do this is that uploading the file into Vector Storage comes with a cost, so it makes sense to upload only useful data.
NOTE: I haven’t tested this thoroughly yet, so it’s possible it may not save enough storage space to justify the effort, but it seems like a logical approach—and it was a fun challenge.
Once we have the cleaned data back, we need to save it as a file and send it to OpenAI for chunking and storage. I’ll admit, I spent a few frustrating hours trying to figure this out, only to realise I had the entire sequence wrong! So, if anyone here is bold enough to try this themselves, the image above outlines the sequence. Essentially, you cannot directly upload a file into your OpenAI Vector Store. First, you upload the file, and then in a separate call, you attach that uploaded file to the store. It’s at this point that OpenAI starts chunking and preparing the data for use.
When you upload the file, you’ll receive a File ID starting with file_. This may seem unremarkable, but it’s actually quite useful, as throughout the process OpenAI assigns different reference numbers, all with clear identifiers: vs_ for Vector Store, file_ for files, asst_ for Assistant, and thread_ for threads.
As an example, a call to add a file to the Vector Store might look like this:
const vsID = `vs_6EvQHxVxxxxxxHbKe3x`;
const vURL = `https://api.openai.com/v1/vector_stores/${vsID}/files`;
console.info(`File ID: ${fileID}`)
// Send the request with JSON body
const vsResponse = await http.post(vURL, {
headers: {
'Authorization': `Bearer ${openAI_Key}`,
"OpenAI-Beta": "assistants=v2",
'Content-Type': 'application/json'
},
data: {
'file_id': fileID,
}
});
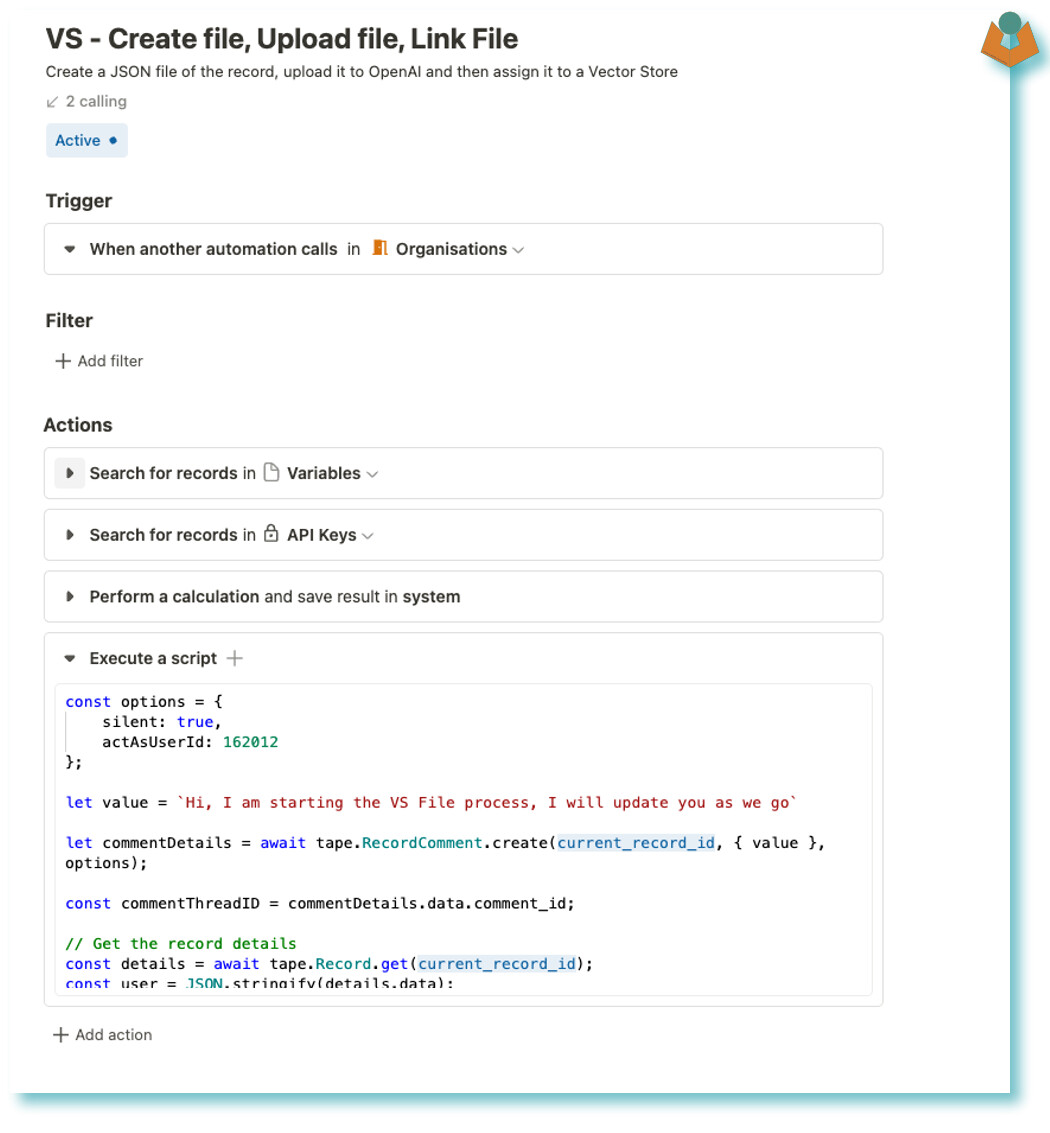
I save the JSON file and the file_id to the record I do this as if the record is updated I will likely want to delete the file from the store and regenerate a new one and upload etc. I have a nightly automation that checks these things in some apps and triggers the process. Oh and in these apps I also add a date field for when the file was created just to make it easy:
// ##### ---- UPDATE THE RECORD ---- #####
console.warn(`Updating the record with the file`);
const updateResponse = await tape.Record.update(current_record_id, {
"fields": {
"vectorestorefile": tapeFileId,
"vs_filedate": current_datetime_local
}
});
So that is the easy bit done we now have some data in our store ready for some AI magic once you have the sequence in your mind it is all fairly normal stuff in a single automation:
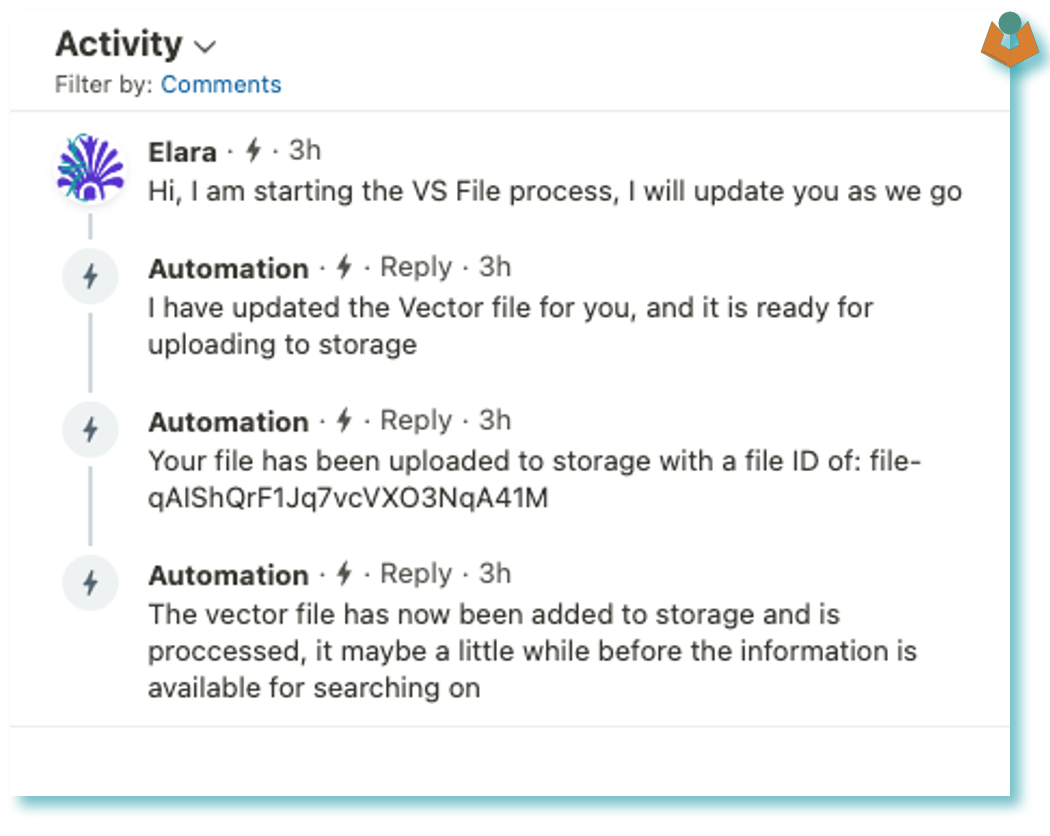
I add comments to the record through the process so I can see the stages:
Using the data
To start using this data, we need an Assistant. You can build these through the API, which is handy if you’re planning to create many of them. However, I simply created one via the website:
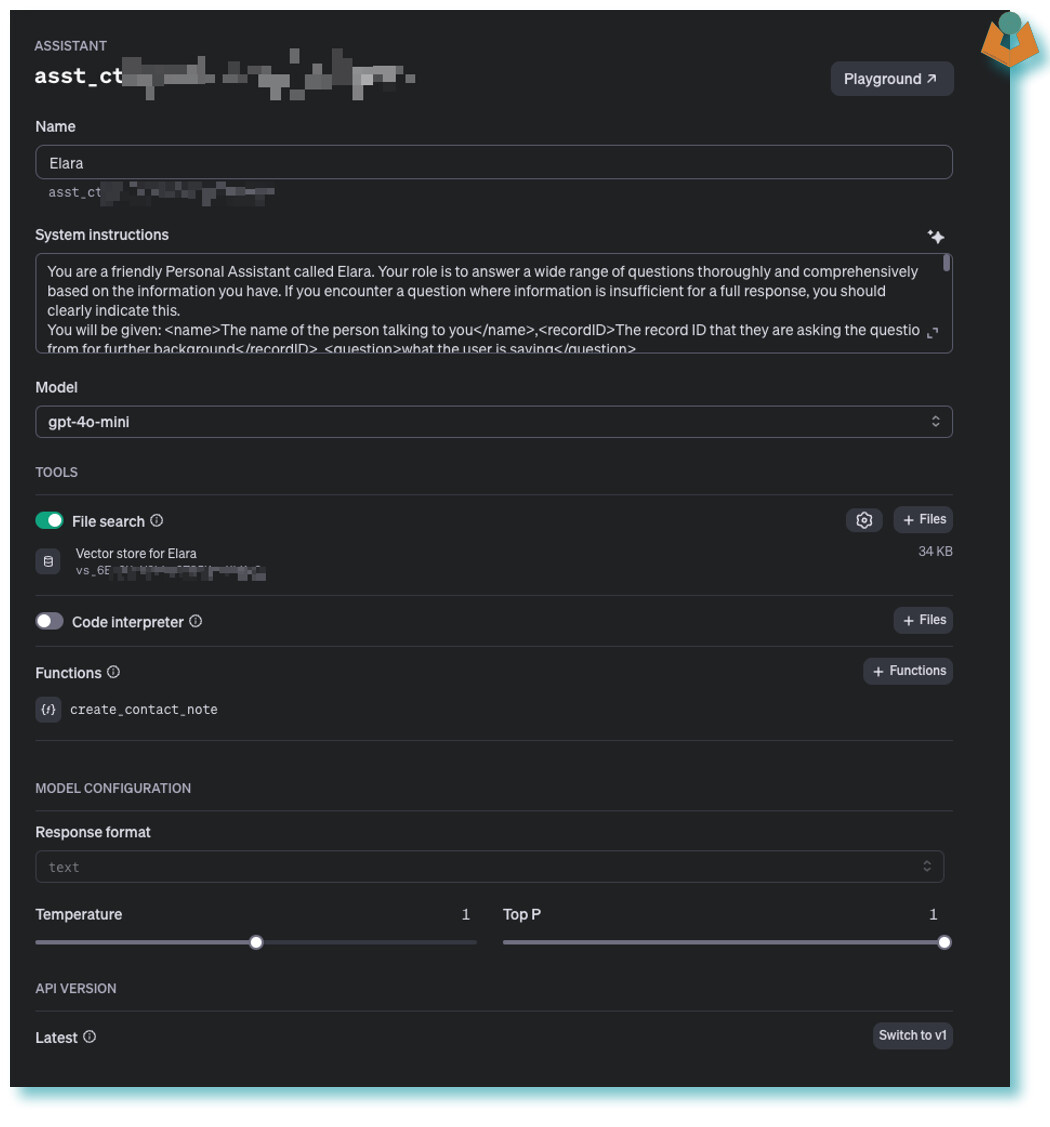
Here, you configure your Assistant’s behaviour, attach the vector store, and add any functions. In the example, you can see I’ve attached a function called create_contact_note, but I won’t dive into those details here.
Once everything is set up, we can begin asking questions. OpenAI has a specific sequence you need to follow, and while it may seem a bit cumbersome for our purposes in Tape, it does make sense in more complex setups. I even asked ChatGPT about the reasoning behind this sequence, and the explanation was mostly logical. But for us, it just adds an extra layer of work! The process goes like this:
1. Create a thread
2. Assign the thread to an Assistant
3. Add a message to the thread
4. Run the thread
5. Poll the run for completion
6. Once the poll shows the run is complete, request the response message
7. Provide the response to the user
8. Repeat steps 3 through 7 as needed.
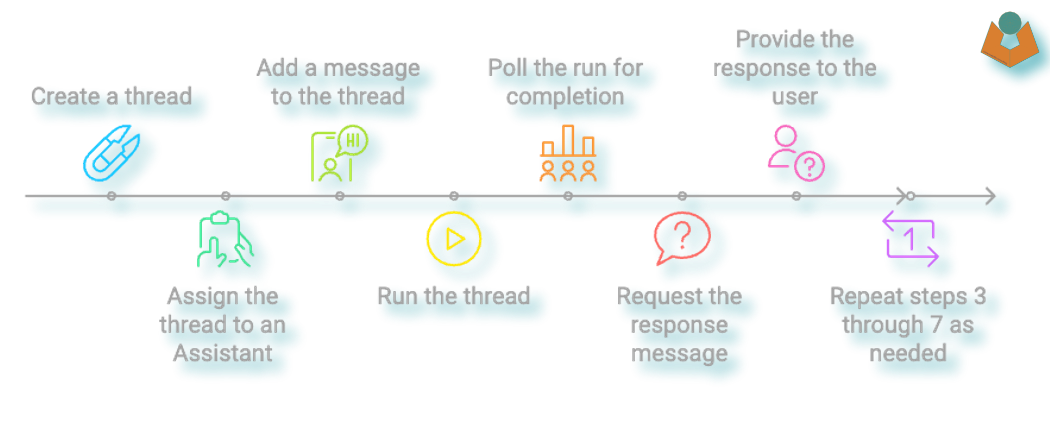
Most of this process is fairly straightforward, though a bit long-winded. However, setting up a polling loop in Tape proves to be quite challenging (perhaps intentionally so), and the built-in delay block has a minimum time of 15 seconds, which is far too long for this use case.
That said, creating the loop is not impossible, as shown in the video. Now, we have a fully functional Virtual AI Assistant that is fully aware of our Tape data and can respond to questions directly within Tape.
In conclusion, this is another demonstration of Tape’s powerful automation capabilities. While there may be other low-code platforms capable of similar tasks, I’m not convinced they offer the same level of integration. And remember, all of this is being achieved without the need for Make, Zapier, or any other automation tools.
Lastly, I previously mentioned that storage comes with a cost, so here’s a clearer picture: the average size of the files I’m uploading is about 3KB, meaning you could store approximately 349,525 records (or files) in just 1GB of space.