A lot of business processes involve the processing of files. Instead of manually looking through a file and copying out the text content, we can automate this task using Tape automations. In this guide, we will create an automation that extracts the text of an attached PDF file and saves it inside the description field of the record.
Automation
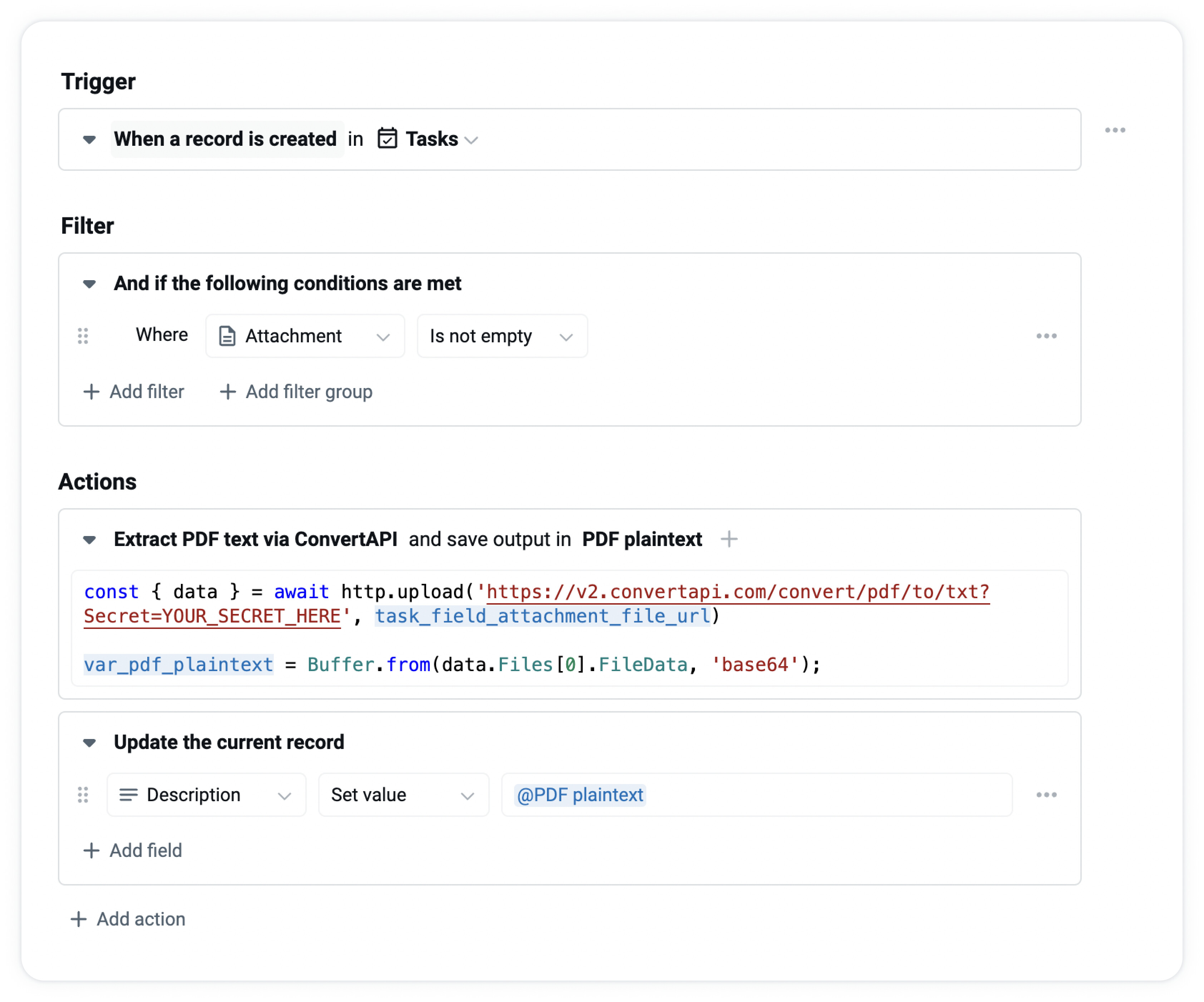
The automation consists of the following steps:
- Trigger when a new task record is created.
- Only continue if the created task has an attachment.
- Use the script action to send the attached file to a conversion API service via the
http.uploadfunction. - Process the HTTP response (it is base64 encoded so we decode it using
Buffer.from) and store the result in our custom variable PDF plaintext - Update the created task’s description with the content of the PDF plaintext variable
We need the following 2 lines of code to perform steps (3) and (4):
const { data } = await http.upload(
'https://v2.convertapi.com/convert/pdf/to/txt?Secret=YOUR_SECRET_HERE',
task_field_attachment_file_url
);
var_pdf_plaintext = Buffer.from(data.Files[0].FileData, 'base64');
The final automation looks like this:
This simple example using PDF files also works for various other file formats like Word documents or PowerPoint presentations. The extracted text can be further processed e.g., by using a conditional action to assign a user based on a keyword (“When the PDF contains the word ‘legal’, assign John”).
Demo Record Video
Let’s test our automation by creating a new task with an attached PDF document:
