“Large amounts of data” in Tape is relative. For some users, 100 records might seem substantial, while others routinely work with 10,000+ records. Tape itself is inconsistent on this front: batch updates are limited to 50 records (suggesting 50 is significant), but search operations work in blocks of 500 (implying 500 is the threshold). From my experience, handling anything under 1,000 records is relatively straightforward; anything beyond that introduces additional complexity.
In this write-up, I’ll demonstrate three approaches to building reports:
- Daily Report - Extracting data from 19,000 records and building a report from up to 1,000 filtered records
- Monthly Report (Standard) - Using the same 19,000 record dataset with a method that scales well into the thousands
- Monthly Report (Alternative) - Working with over 50,000 data points using a single-record architecture
These demonstrations are based on cryptocurrency price tracking.
Before we begin, a disclaimer: these workflows and apps have been built specifically for this demonstration. If you genuinely want to track cryptocurrency prices (rather than just learning Tape techniques), a dedicated time-series database like InfluxDB combined with Grafana would probably be more appropriate. However, these examples showcase Tape’s versatility and capability to handle such workloads.
Also this has turned out long - so long I had to put it across two posts
What Are We Working With?
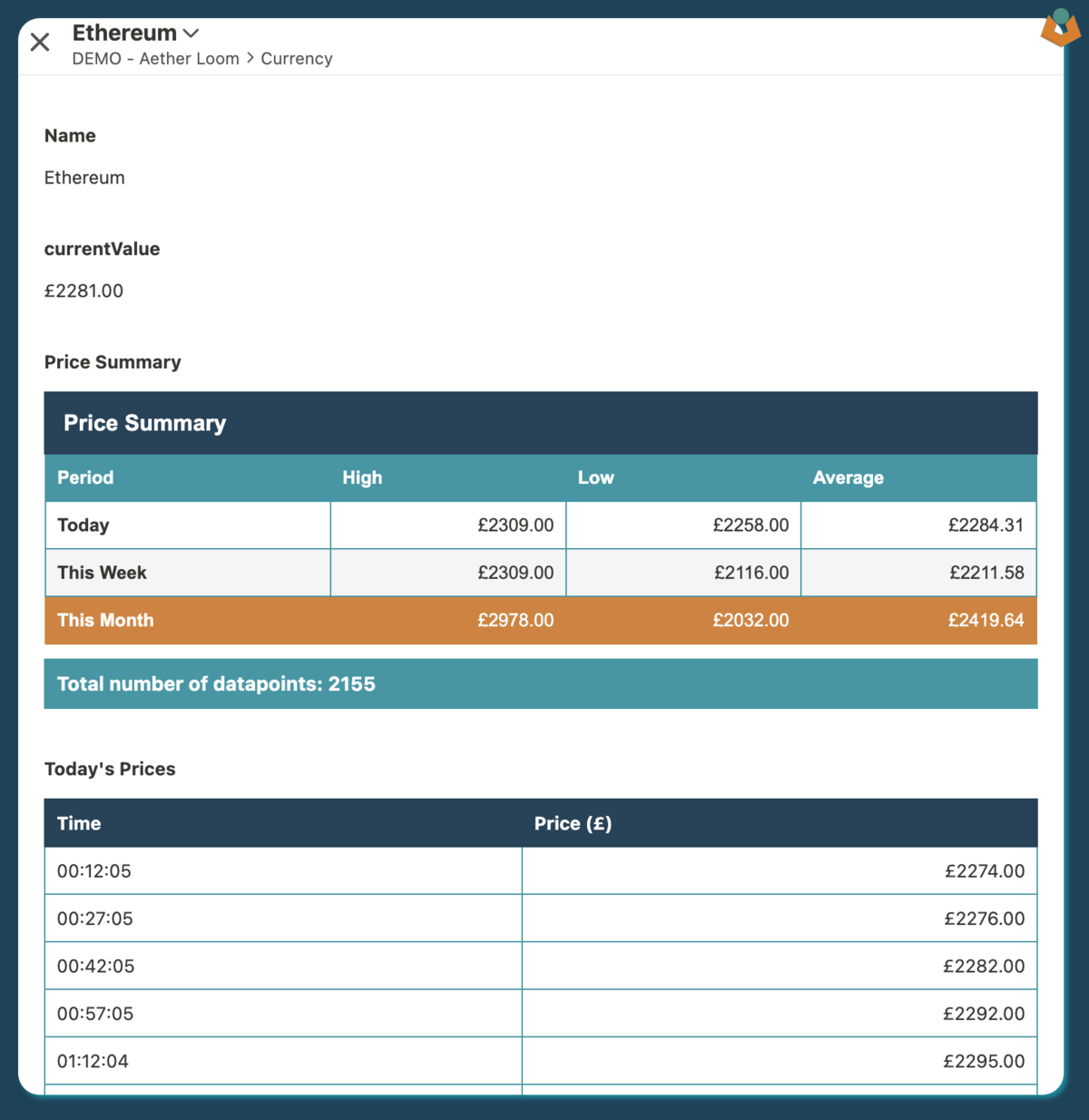
For the first two demos, we have an app containing records tracking Bitcoin and Ethereum prices. An automation runs every 15 minutes, retrieves current prices, and creates a record for each cryptocurrency with the date/time and price. That’s two records every 15 minutes. After running for several months, we now have over 19,000 records, providing the dataset for our first two demonstrations.
Demo One: Daily Report
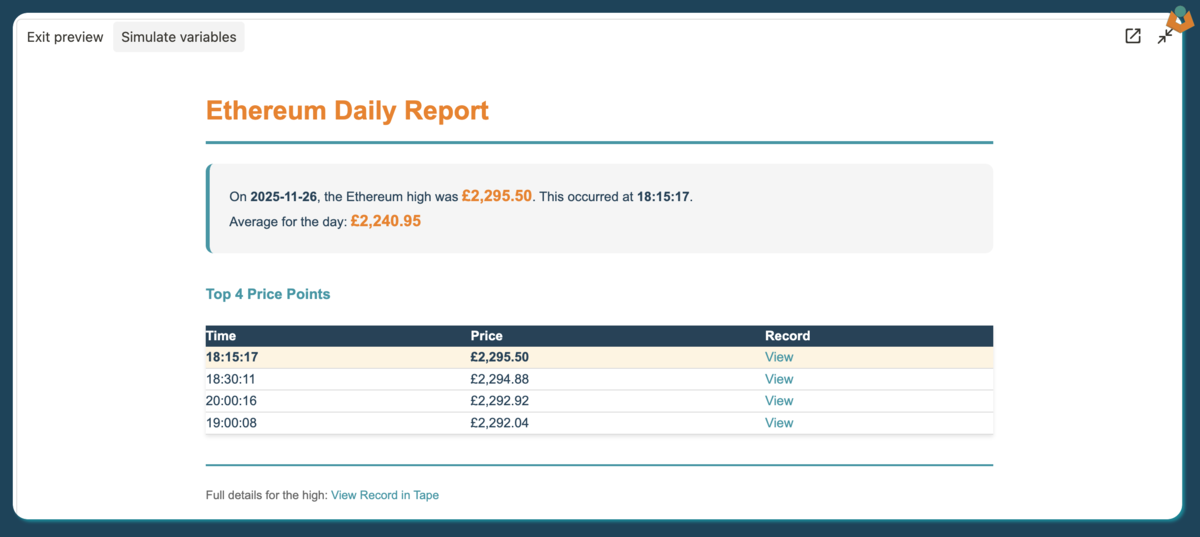
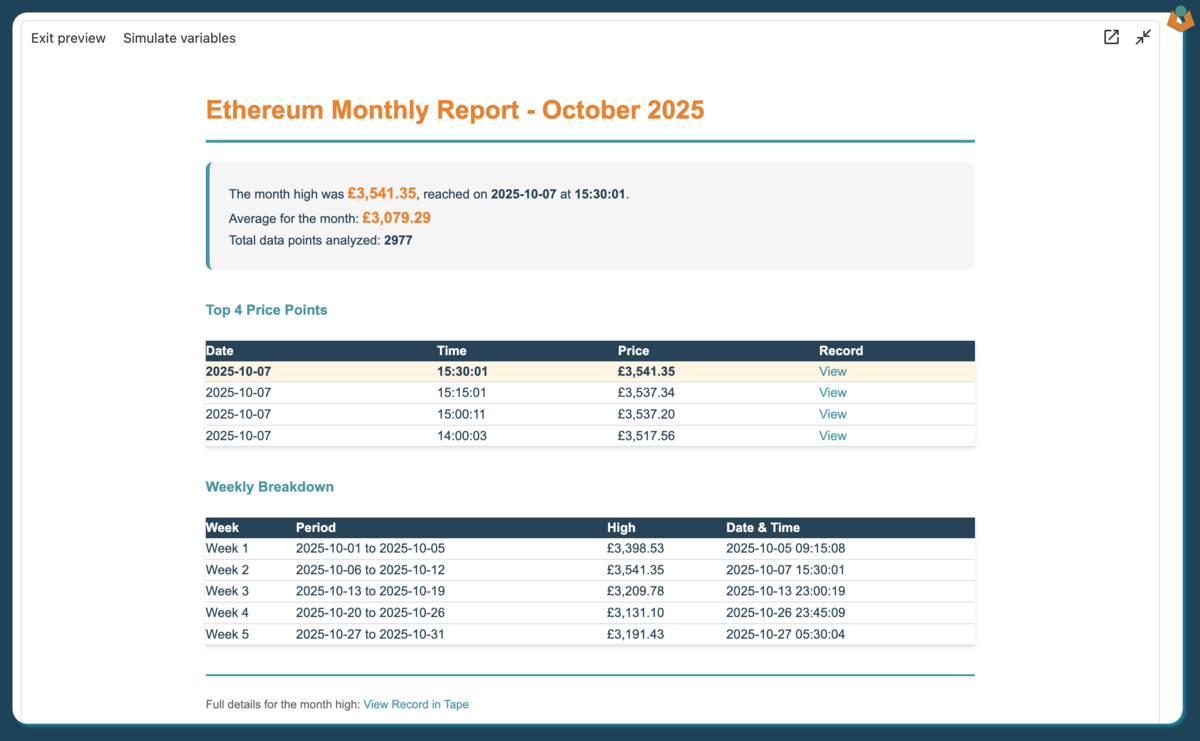
We’ll produce a daily report highlighting Ethereum’s price movements from yesterday. Running the PDF simulation shows the report that will be generated, then we can examine the automation in detail.
The report is generated from a single variable passed to a PDF block and includes:
- A summary section with the date, maximum price, average price, and the time when the maximum occurred
- A table showing the top 4 price points, their timestamps, and links to the relevant records
- A separate link to the highest value record
Examining the automation reveals just three blocks:
- Search for and collect yesterday’s records
- Extract the data and build the report
- Output the report to the PDF block
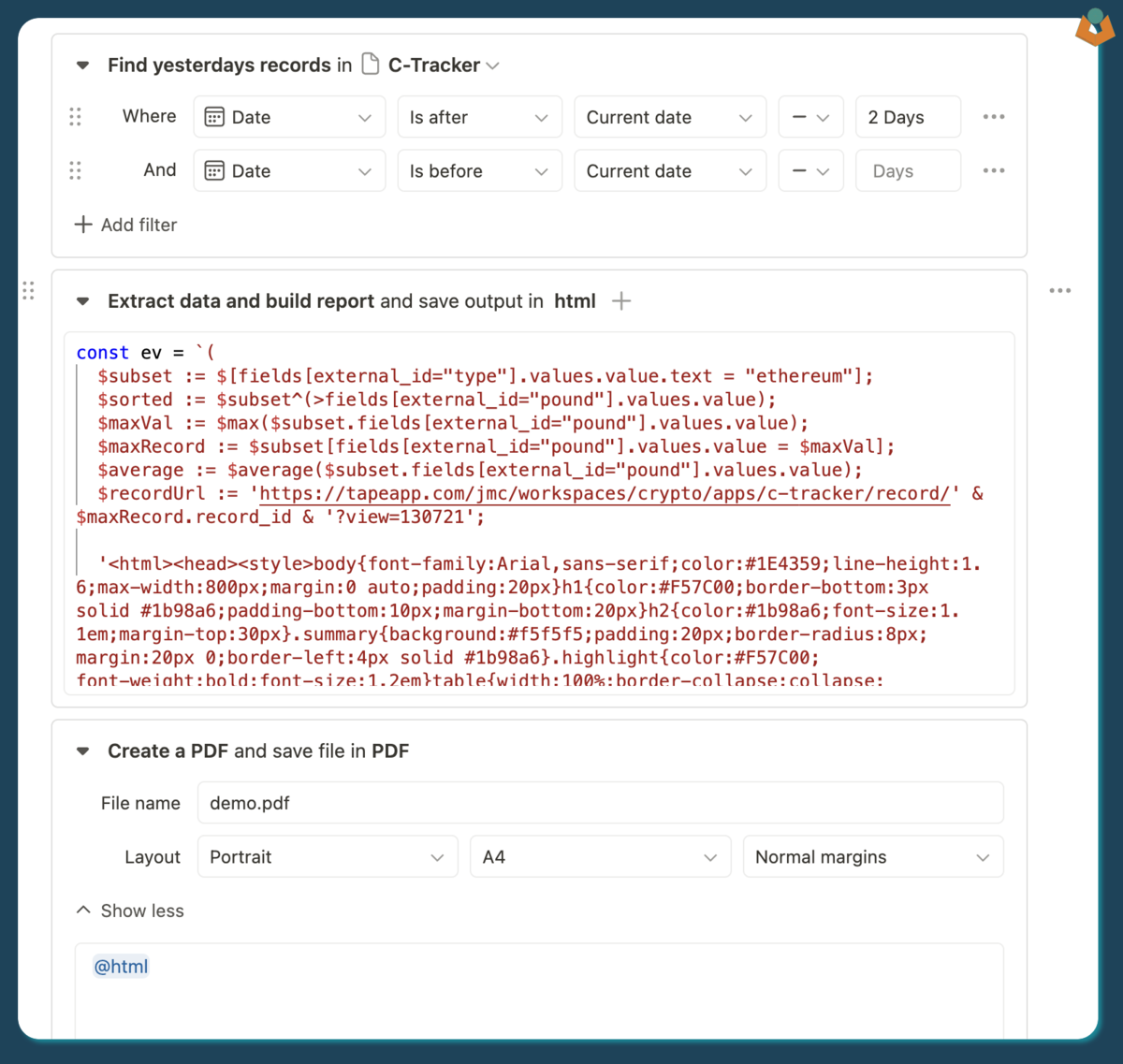
The second stage is where the magic happens. What you can achieve when handling up to 1,000 records is impressive. In my view, this is the sweet spot in Tape, if you can reduce your collection to 1,000 records or fewer, you unlock significant capabilities.
In the first part, we build our evaluate string. This single expression handles everything: filtering the collection into a subset, finding maximum and average values, building record links, and assembling everything into a table. At the end of the script, we have an evaluate command that runs our string on the records from our search. Effectively, this is two lines of code (though one is admittedly very long).
Let’s break it down. The critical part for this demo is the first chunk of code, where we perform the heavy data processing. We’re leveraging JSONata’s power to build variables and use them all within a single string:
$subset := $[fields[external_id="type"].values.value.text = "ethereum"];
$sorted := $subset^(>fields[external_id="pound"].values.value);
$maxVal := $max($subset.fields[external_id="pound"].values.value);
$maxRecord := $subset[fields[external_id="pound"].values.value = $maxVal];
$average := $average($subset.fields[external_id="pound"].values.value);
$recordUrl := 'https://tapeapp.com/jmc/workspaces/crypto/apps/c-tracker/record/' &
$maxRecord.record_id & '?view=130721';
Breaking down each line:
$subset- Filters the data to extract only ‘Ethereum’ records into a new subset$sorted- Sorts the subset by the ‘pound’ value. The^symbol indicates sorting, while>specifies the field and direction (descending order, highest to lowest)$maxVal- Finds the highest value. We could have extracted this from the first record in our sorted set, but this approach is equally simple and demonstrates a useful feature$maxRecord- Finds the record with the highest value by searching our subset for the record whose pound field matches our maximum value$average- Calculates the average value of the ‘pound’ field across our entire subset$recordUrl- Builds a link to the record with the highest value
We’ve effectively created a series of variables using different evaluate expressions, all ready to be inserted into our final HTML output string:
'<html><head><style>
body{font-family:Arial,sans-serif;color:#1E4359;line-height:1.6;max-width:800px;margin:0 auto;padding:20px}
h1{color:#F57C00;border-bottom:3px solid #1b98a6;padding-bottom:10px;margin-bottom:20px}
h2{color:#1b98a6;font-size:1.1em;margin-top:30px}
.summary{background:#f5f5f5;padding:20px;border-radius:8px;margin:20px 0;border-left:4px solid #1b98a6}
.highlight{color:#F57C00;font-weight:bold;font-size:1.2em}
table{width:100%;border-collapse:collapse;margin:20px 0;box-shadow:0 2px 4px rgba(0,0,0,0.1)}
th{background:#1E4359;color:white;padding:12px;text-align:left;font-weight:600}
td{padding:12px;border-bottom:1px solid #ddd}
tr:hover{background:#f9f9f9}
.top-record{background:#fff3e0;font-weight:bold}
a{color:#1b98a6;text-decoration:none;font-weight:500}
a:hover{text-decoration:underline}
.footer{margin-top:30px;padding-top:20px;border-top:2px solid #1b98a6;font-size:0.9em;color:#666}
</style></head><body>
<h1>Ethereum Daily Report</h1>
<div class="summary">
<p>On <strong>' & $substringBefore($maxRecord.fields[external_id="date"].values.start, ' ') &
'</strong>, the Ethereum high was <span class="highlight">' &
$maxRecord.fields[external_id="pound"].values.formatted & '</span>.
This occurred at <strong>' & $substringAfter($maxRecord.fields[external_id="date"].values.start, ' ') &
'</strong>.</p>
<p>Average for the day: <span class="highlight">' & $formatNumber($average, '£#,##0.00') & '</span></p>
</div>
<h2>Top 4 Price Points</h2>
<table>
<thead>
<tr><th>Time</th><th>Price</th><th>Record</th></tr>
</thead>
<tbody>' & (
'<tr class="top-record"><td>' &
$substringAfter($sorted[0].fields[external_id="date"].values.start, ' ') &
'</td><td>' & $sorted[0].fields[external_id="pound"].values.formatted &
'</td><td><a href="https://tapeapp.com/jmc/workspaces/crypto/apps/c-tracker/record/' &
$sorted[0].record_id & '?view=130721">View</a></td></tr>' &
'<tr><td>' & $substringAfter($sorted[1].fields[external_id="date"].values.start, ' ') &
'</td><td>' & $sorted[1].fields[external_id="pound"].values.formatted &
'</td><td><a href="https://tapeapp.com/jmc/workspaces/crypto/apps/c-tracker/record/' &
$sorted[1].record_id & '?view=130721">View</a></td></tr>' &
'<tr><td>' & $substringAfter($sorted[2].fields[external_id="date"].values.start, ' ') &
'</td><td>' & $sorted[2].fields[external_id="pound"].values.formatted &
'</td><td><a href="https://tapeapp.com/jmc/workspaces/crypto/apps/c-tracker/record/' &
$sorted[2].record_id & '?view=130721">View</a></td></tr>' &
'<tr><td>' & $substringAfter($sorted[3].fields[external_id="date"].values.start, ' ') &
'</td><td>' & $sorted[3].fields[external_id="pound"].values.formatted &
'</td><td><a href="https://tapeapp.com/jmc/workspaces/crypto/apps/c-tracker/record/' &
$sorted[3].record_id & '?view=130721">View</a></td></tr>'
) & '</tbody>
</table>
<div class="footer">
<p>Full details for the high: <a href="' & $recordUrl & '">View Record in Tape</a></p>
</div>
</body></html>'
)`;
We could have built this with multiple lines of JSONata evaluates, such as:
const subset = jsonata(`$[fields[external_id="type"].values.value.text = "ethereum"]`)
.evaluate(record_collection_c_tracker);
const sorted = jsonata(`^(>fields[external_id="pound"].values.value)`)
.evaluate(subset);
However, building it all within one string and then running a single evaluate is more efficient for processing.
Demo Two: Monthly Report (Standard Approach)
This time we’ll use the same data but produce a monthly report. This takes longer as our working dataset is nearly 6,000 records (potentially higher). For this report, we only have two blocks: a script and our PDF creation. Let’s break down the script.
This report requires extensive date manipulation, which isn’t straightforward in JSONata. Much of the code handles dates, making it appear longer and more complex than it actually is. The first part gets the date details for the month we want to work with. We could achieve this in fewer lines by nesting date_fns commands, but that would make the logic harder to follow:
Step 1: Date Preparation
const now = new Date();
const firstDayLastMonth = date_fns.startOfMonth(date_fns.subMonths(now, 1));
const lastDayLastMonth = date_fns.endOfMonth(date_fns.subMonths(now, 1));
const startDate = date_fns.format(firstDayLastMonth, 'yyyy-MM-dd');
const endDate = date_fns.format(lastDayLastMonth, 'yyyy-MM-dd');
const monthName = date_fns.format(firstDayLastMonth, 'MMMM yyyy');
Step 2: Build Filters
We need to build a collection, and for that we need filters. Now that we have our first and last dates, we can construct our filter:
const filters = [
{
field_id: 669144,
field_type: 'single_date',
match_type: 'on_or_after',
relative_date_type: 'exact_date',
values: [{ value: startDate }],
type: 'date'
},
{
field_id: 669144,
field_type: 'single_date',
match_type: 'on_or_before',
relative_date_type: 'exact_date',
values: [{ value: endDate }],
type: 'date'
}
];
Notice the match_type: 'on_or_after', which is very useful and avoids the “-x days” approach, simplifying our date-finding logic at the top. You can think of this section as equivalent to the search block in our first example.
Step 3: Fetch the Collection
We still don’t have a collection, but we’re prepared. Now we need to retrieve one. Since our dataset exceeds the 1,000 record threshold, we must use a loop; there’s no avoiding it:
Now i have used a function here which means i should be able to copy paste it into any other app and it work just fine, lets take a look at it as it contains an incredibly useful thing that Tape does which helps simplify the code immensely and that is in this first part:
// First, get the total count
const { data: { total } = {} } = await tape.Record.getManyFiltered({
appId,
limit: 1,
filters
});
console.log(`Total records to fetch: ${total}`);
When you run a getManyFilteredin tape regardless of how many you return (limit restriction) it returns a field named total and this contains the total number of records that match the filter used. Now I can not stress how useful this is it provides us with a firm number and from that we can work out how many loops we are going to have to make and avoids the need for all sorts of checks that you would have to build into your loop if it were not for this.
The next part of our function takes this new information and uses it to calculate the number of loops needed by taking our new found ‘total’ and dividing it by the maximum number of records we can get in a loop ‘500’
// Calculate how many loops we need (500 records per page)
const pageSize = 500;
const totalLoops = Math.ceil(total / pageSize);
let allRecords = [];
let cursor = undefined;
We also setup our allRecords array ready for our record data and our cursor variable that tells our loops were we have got to in the process more on this in a bit.
The last part of our function performs the actually collecting:
for (let i = 0; i < totalLoops; i++) {
const params = { appId, limit: pageSize, filters };
if (cursor) params.cursor = cursor;
const { data: { records = [], cursor: nextCursor } = {} } =
await tape.Record.getManyFiltered(params);
allRecords.push(...records);
console.log(`[${i + 1}/${totalLoops}] Fetched ${records.length}, total ${allRecords.length}`);
cursor = nextCursor;
// Safety check - if no more records, stop
if (records.length === 0) break;
}
return allRecords;
}
As we have the total number of loops we can set a loop number and count each loop as long as our loop number is less than our total loops: for (let i = 0; i < totalLoops; i++)
Step 4
Back to our script block we now need to trigger our function by calling it and passing our variables iso they can be slotted into the ‘placeholders’:
// Step 4: Fetch the data
const appId = 65836;
const allRecords = await fetchAllFiltered(appId, filters);
console.log(`Fetched total records: ${allRecords.length}`);
We set our appId, and we already have our filters built from Step 2. Our function was inventively named fetchAllFiltered, and we are going to put the return value into a variable called allRecords.
NOTE: As a quick note about
return, you could structure this differently by initialising theallRecordsvariable before the function withlet allRecords = [], rather than inside it. You could then useallRecords = await fetchAllFiltered(appId, filters);without using areturnstatement at the end of the function. To be honest though, in this case it adds unnecessary complexity and makes the function less portable if you want to use it in another app.
The Data Manipulation
Everything we have done so far has been building our primary collection and is exactly why I said in Demo One the sweet spot was sub 1000 records because as soon as we go over that magic number we have to build a lot of code (which admittedly is mostly reusable) before we get anywhere near the actual manipulating of the data. Now i may as well cover this off here those of you that have been following along will have noticed that I talk about 1000 records and yet in our loops we are limiting our collection size to 500 (worth noting also that the default is that 50 number again) however when you do an unlimited search in a search block you can return 1000 records to a collection:
10:35:46.866] Action execution started.
[10:35:55.877] Collected 1000 records.
[10:35:55.879] Action execution succeeded.
this is why 1000 is the magic number, but why does the search block return a max of 1000 records not the 500 (or 50)? I believe because it will run one loop for you if it receives a cursor on the first retrieval.
We have now got our data nearly 6000 records:
[15:28:38.601] Fetched total records: 5955
now we need to do something with this mass of data however because our report is monthly its actually more complicated that our daily one we are going to
- Have a summary section at the top as before
- The top 4 price points again however
- Then have added a Weekly Breakdown which was; I will admit was a little tricky to get working, and in many ways is not really important as the other parts of the report show manipulating data from a large data set but lets go through it anyway as it is something that could be needed and shows an interesting method.
Step 5
Step 5 is more date work to prepare for building that week table and take our first day of our working month from step 1 firstDayLastMonth find the Monday of that week and then we loop through until our Monday date is not less than the last day of our working month and this will give us our weeks:
// Step 5: Calculate week boundaries for the month
const weeks = [];
let currentWeekStart = date_fns.startOfWeek(firstDayLastMonth, { weekStartsOn: 1 }); // Monday is the start week day
while (currentWeekStart <= lastDayLastMonth) {
const weekEnd = date_fns.endOfWeek(currentWeekStart, { weekStartsOn: 1 }); // Sunday is the end week day
// Cap both start and end to month boundaries
const cappedStart = currentWeekStart < firstDayLastMonth ? firstDayLastMonth : currentWeekStart;
const cappedEnd = weekEnd > lastDayLastMonth ? lastDayLastMonth : weekEnd;
weeks.push({
start: date_fns.format(cappedStart, 'yyyy-MM-dd'),
end: date_fns.format(cappedEnd, 'yyyy-MM-dd'),
label: `Week ${weeks.length + 1}`
});
currentWeekStart = date_fns.addWeeks(currentWeekStart, 1);
}
console.log('Week boundaries:', JSON.stringify(weeks));
with the result of our endeavours looking like:
[11:18:01.576] Week boundaries:, [{"start":"2025-10-01","end":"2025-10-05","label":"Week 1"},{"start":"2025-10-06","end":"2025-10-12","label":"Week 2"},{"start":"2025-10-13","end":"2025-10-19","label":"Week 3"},{"start":"2025-10-20","end":"2025-10-26","label":"Week 4"},{"start":"2025-10-27","end":"2025-10-31","label":"Week 5"}]
Step 6
Date handling in JSONata could be described as one of its weaknesses and I tried a few different ways to get this to work but in the end this seemed the easiest path and it shows something quite useful. What we do in step 6 is actually build the weeks table outside of JSONata were we can handle dates better I am not really sure I like the way I have done this part but and the details of it don’t really matter however what we are in effect doing is using JavaScript to build part of our JSONata expression before in step 7 we ‘inject’ it into our full expression (honestly it makes my brain hurt and i built it):
// Step 6: Build weekly table rows FIRST (before JSONata)
let weeklyTableRows = '';
weeks.forEach((week, idx) => {
const weekSubset = allRecords.filter(r => {
const recordDate = r.fields.find(f => f.external_id === 'date')?.values?.[0]?.start;
if (!recordDate) return false;
const dateOnly = recordDate.split(' ')[0];
return dateOnly >= week.start && dateOnly <= week.end;
});
if (weekSubset.length > 0) {
const ethereumRecords = weekSubset.filter(r =>
r.fields.find(f => f.external_id === 'type')?.values?.[0]?.value?.text === 'ethereum'
);
if (ethereumRecords.length > 0) {
const maxPrice = Math.max(...ethereumRecords.map(r =>
r.fields.find(f => f.external_id === 'pound')?.values?.[0]?.value || 0
));
const maxRecord = ethereumRecords.find(r =>
r.fields.find(f => f.external_id === 'pound')?.values?.[0]?.value === maxPrice
);
const dateTime = maxRecord.fields.find(f => f.external_id === 'date')?.values?.[0]?.start || '';
const formatted = maxRecord.fields.find(f => f.external_id === 'pound')?.values?.[0]?.formatted || '';
weeklyTableRows += `<tr><td>${week.label}</td><td>${week.start} to ${week.end}</td><td>${formatted}</td><td>${dateTime}</td></tr>`;
}
}
});
console.log('Weekly table rows:', weeklyTableRows);
Step 7
Moving swiftly on to step seven we now start building our final expression: filtering, calculating and building just as we did in Demo One, again there is a a lot of html in the second part however the first part is were the heavy lifting happens:
$subset := $[fields[external_id="type"].values.value.text = "ethereum"];
$sorted := $subset^(>fields[external_id="pound"].values.value);
$maxVal := $max($subset.fields[external_id="pound"].values.value);
$maxRecord := $subset[fields[external_id="pound"].values.value = $maxVal];
$average := $average($subset.fields[external_id="pound"].values.value);
$recordUrl := 'https://tapeapp.com/jmc/workspaces/crypto/apps/c-tracker/record/' & $maxRecord.record_id & '?view=130721';
Is identical to the first part of Demo one were we build our variables before we slot them into our HTML and as for that pesky weeks table we add that is here:
'</tbody></table><h2>Weekly Breakdown</h2><table><thead><tr><th>Week</th><th>Period</th><th>High</th><th>Date & Time</th></tr></thead><tbody>${weeklyTableRows}</tbody></table>
and then obviously we run the JSONata expresion:
var_html = jsonata(ev).evaluate(allRecords);
What does this mean
I think there are a few take aways from this:
- Get you collections bellow 1000 records whenever you can. As soon as you start looping to build a collection it is a killer on the automation run time.
- Once you have that collection whatever the size be it 2 records or 20,000 it doesn’t matter you can pull data out, run calculations on it and output it however you like by using JSONata.
- If your JSONata expression is easier to build in JavaScript and then ‘inject’ into the full expression then you can.
- Avoid loops! as far as i can see when handling large amounts of data loops are your enemy it doesn’t matter how well you build them as soon as you start looping through anything it uses time and actions.
This part is not really 100% accurate (hopefully what i say next won’t be to much of an insult to the Tape team as i reduce something vey complex into an over simplification) but I think is a good way of looking at it:
- A record in Tape is just a chunk of JSON when you view a record on the screen it is just an HTML template that puts the JSON data were it should be for you to read a little like our report.
- An App is just a collection of these JSON ‘files’
This means that everything you can see and more is available in a formatted bit of text this can be rapidly filtered, extracted, changed and moved or displayed.