It all started when I tried to open a new browser tab on my phone and received a warning that I already had 500 tabs open and couldn’t open any more. It also gave me an option to close all my tabs.
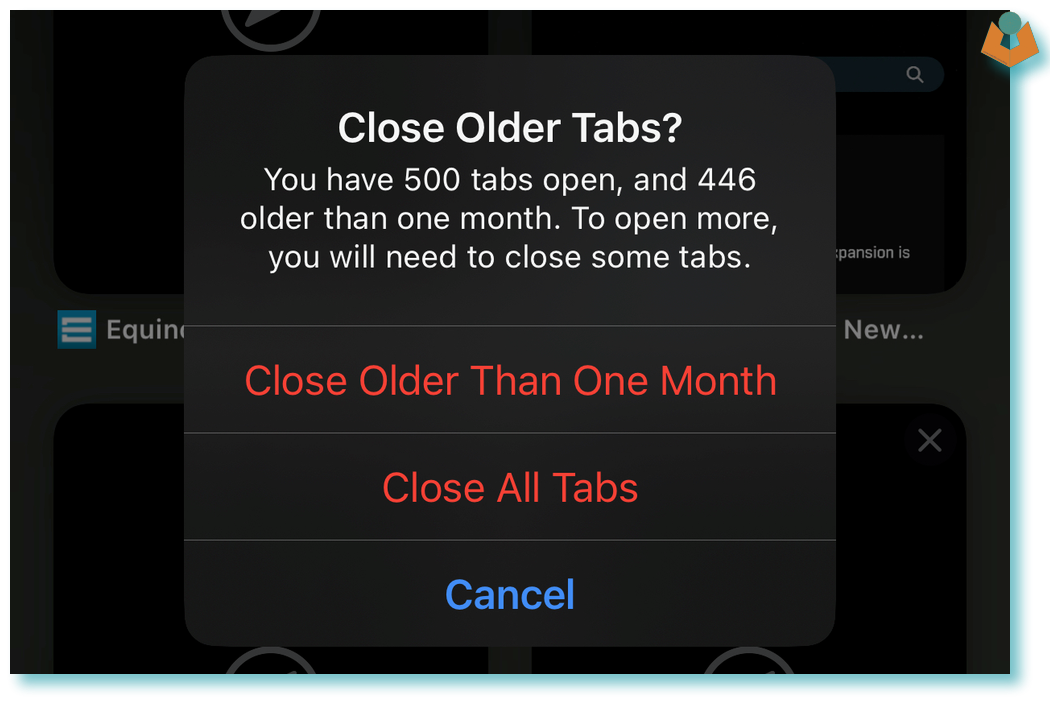
I didn’t want to close all my tabs as they were like bookmarks for me. Web bookmarking tools are a bit like note-taking apps for me—incredibly important for daily life, yet finding one I want to stick with is impossible as there always seems to be something I don’t like.
Anyway, the day had come when I needed to do something about my open tabs and therefore I needed a bookmarking tool. I have always liked Raindrop, a nice cross-platform tool for bookmarks that can also handle highlighting and annotations. So, for no good reason other than it came to mind quicker than any other tool, I chose to use it to get my open tabs bookmarked.
I did not want to manually add 500-odd web pages to Raindrop and then manually close the tabs, so automation was required. I opened Apple Shortcuts only to find that Raindrop didn’t offer any integration. However, not to be deterred, I remembered that Raindrop has a public API. So, a little while later, I had an Apple Shortcut that looped through all my open bookmarks, sent the URL to Raindrop (sorry Raindrop, I didn’t use your batch upload), and closed the open tab.
Perfect! I now had 500+ URLs in my Raindrop account and no open tabs in Safari. At this stage, you may be thinking, “What has this got to do with Tape?” and you are correct—nothing, yet!
However, this is where the rabbit hole swallowed me. I now had a lot of URLs in a bookmarking tool, some duplicates, and no sorting. So, while I had solved one problem, I had created another.
Raindrop has quite a good built-in system to help you organise your ‘raindrops’; however, that only works if you already have a structure with some raindrops filed. I didn’t, so I needed a different solution and that’s when I turned to Tape.
What did I want to achieve?
- I needed to build a structure to sort my URLs
- I needed to de-dupe my URLs
- I finally needed to put all my URLs into my chosen structure
Get URLs out of Raindrops and into Tape
The first step was to get the URLs into Tape. Having been a little unkind to Raindrop with my Shortcuts automation where I had uploaded one at a time, I wanted to try and be a little nicer from now on. They have ‘batch’ options in their API, so I thought I would use that. However, this brought in the first Tape limitation that I met.
Raindrop limits its bulk API to 50 records, and I wanted over 500, so I wrote a script block to call a page at a time, add all the URLs to an array, and then de-dupe the list. My plan was then to loop through each URL and create a record for each URL:
const api = `Bearer ${collected_api_key_field_apikey_value}`;
const url = 'https://api.raindrop.io/rest/v1/raindrops/0';
let totalPages = 0;
let currentPage = 0;
let raindrops = [];
// Initial request to get total drops
let response = await http.get(`${url}?perpage=1&page=1`, {
headers: {
"Authorization": api
}
});
// console.log(JSON.stringify(response));
// Extract total number of drops
const totalDrops = jsonata('count').evaluate(response.data);
console.info('Total Drops', totalDrops);
// Calculate total pages
totalPages = Math.ceil(totalDrops / 50);
console.info('Total Pages', totalPages);
// Loop through each page and fetch raindrops
for (currentPage = 0; currentPage < totalPages; currentPage++) {
response = await http.get(`${url}?perpage=50&page=${currentPage}`, {
headers: {
"Authorization": api
}
});
// Extract links from the response and add to raindrops array
const items = jsonata('items.link').evaluate(response.data);
if (items) {
raindrops = raindrops.concat(items);
}
}
console.warn('___');
console.log('Total items fetched', raindrops.length);
// Remove duplicates by converting to a Set and back to an array
const uniqueUrlsSet = new Set(raindrops);
const uniqueRaindrops = Array.from(uniqueUrlsSet);
console.info('Unique items count', uniqueRaindrops.length);
var_drops = uniqueRaindrops;
However, Tape couldn’t perform this automation within its limits (time or actions). I needed a different approach. The obvious way (at least to me at the time) as I was working in ‘pages’ was to work with a page at a time, but that meant I needed to track what page I was on.
I created a ‘Pages’ app. All this was going to do was handle the tracking of pages and retrieval of the URLs:
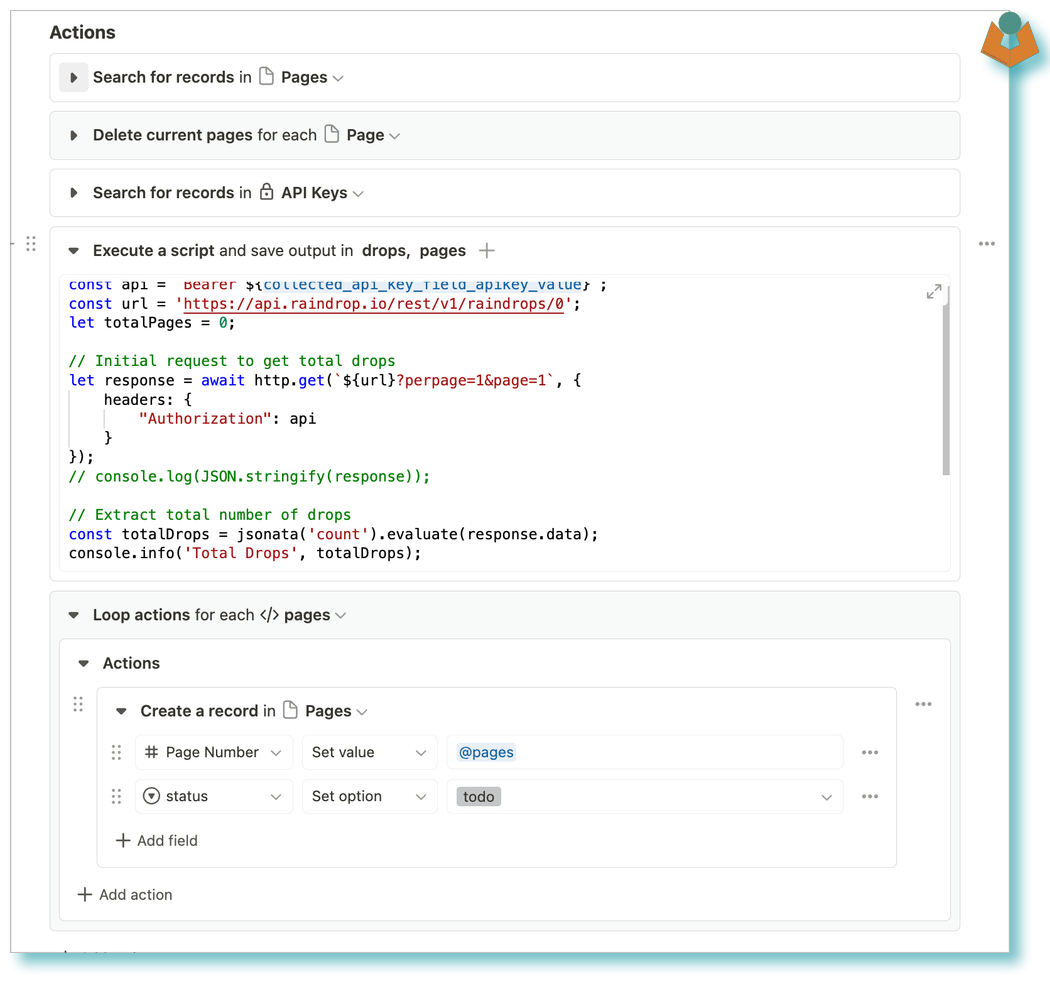
The script was simple: go and find out how many pages of URLs there were and put that number in an array. Then the workflow would loop through the array and create the relevant number of pages.
const api = `Bearer ${collected_api_key_field_apikey_value}`;
const url = 'https://api.raindrop.io/rest/v1/raindrops/0';
let totalPages = 0;
// Initial request to get total drops
let response = await http.get(`${url}?perpage=1&page=1`, {
headers: {
"Authorization": api
}
});
// console.log(JSON.stringify(response));
// Extract total number of drops
const totalDrops = jsonata('count').evaluate(response.data);
console.info('Total Drops', totalDrops);
// Calculate total pages
totalPages = Math.ceil(totalDrops / 50);
console.info('Total Pages', totalPages);
var_pages = Array.from({ length: totalPages }, (_, i) => i + 1);
console.info(JSON.stringify(var_pages))
This gave me a list of pages I could then run a separate workflow on:
For anyone who is interested, the script is:
const api = `Bearer ${collected_api_key_field_apikey_value}`;
const url = 'https://api.raindrop.io/rest/v1/raindrops/0';
let response = await http.get(`${url}?perpage=50&page=${page_field_page_number_decimal_value}`, {
headers: {
"Authorization": api
}
});
console.log(JSON.stringify(response));
var_drops = jsonata('items.link').evaluate(response.data);
console.info(var_drops);
After running the above on every page, we have all our ‘Drops’ in Tape. They are de-duped and ready for the next stage.
Categorisation
I needed a way to sort/file my Drops (URLs). For that, I turned to AI. ChatGPT would have been great, but for that, I would have needed to not only retrieve the contents of each page (more on this later) but also send each page up to be analysed. This is a lot of tokens, but also, I wasn’t trying to, at this stage, allocate a category to each drop but rather build a structure to file drops in.
The way I felt I could do this was by using Perplexity AI. For those who don’t know, Perplexity is simply put, a tool that mixes web search with LLM to produce smart searches. They have a public API, and that’s what we are going to use.
I wasn’t sure how many URLs I could send in one go, so I built a script block that put all of my URLs into an array and then randomly picked a number of them, put those in a new array, and then sent this array to Perplexity and asked for a structure that was suitable for my URLs.
I actually ran this with 100, then 300, and finally 500 URLs and examined the structure it provided with each run.
The next part I did manually, which was to go through the three AI-produced structures and build one I was happy with. This was mainly based on the 500 URL batch.
At this stage, I still had all the URLs in my Raindrop account and I needed a blank slate. So, I deleted everything and then manually put in my category (or collection as Raindrop calls them) structure.
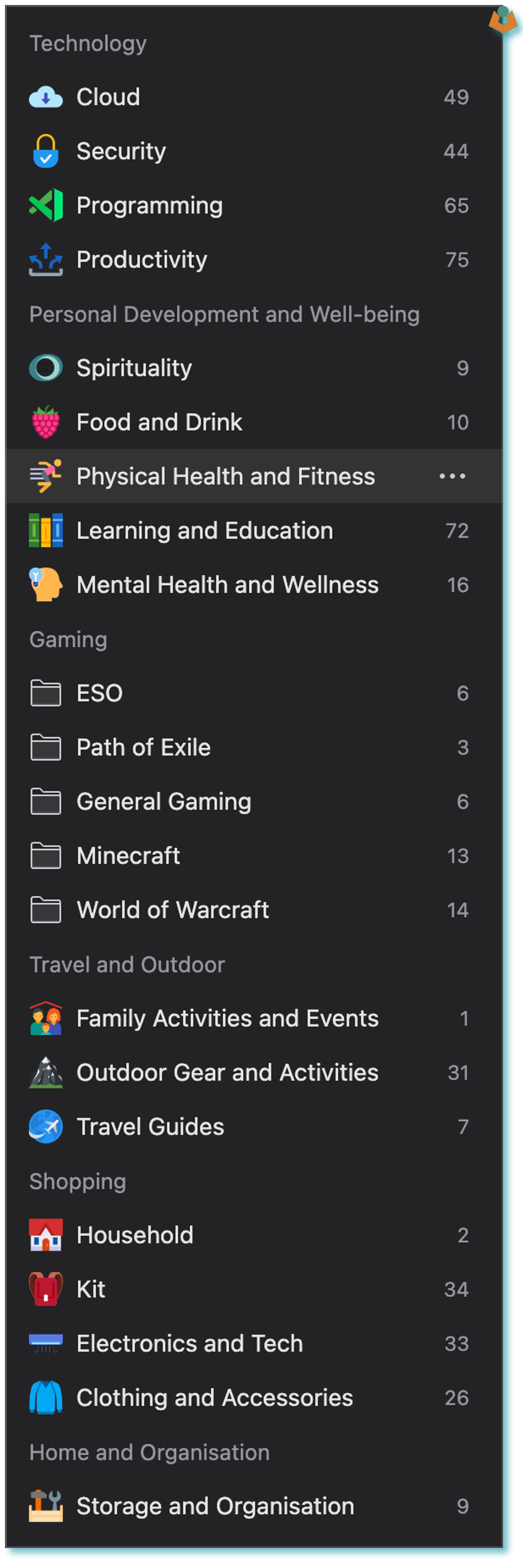
Categorisation Part 2
We now have our categorisation options defined. The next stage is to pass our URLs back to the AI along with the categories and tags. It may feel like this is a duplication of work; however, I have done it this way round as we can restrict the AI to use only the list of categories we want. Otherwise, we will end up with a huge number of categories with very little in them.
However, before we can pass the pages and collections to the AI we need them in Tape. Raindrops has a ‘Collections’ endpoint which we can use to pull them into Tape I setup two more apps in Tape to hold our Collections and Tags then run a simple workflow to get the collections from Raindrops extract an array of the IDs loop through the IDs creating a record for each and adding the name and ID to the record:
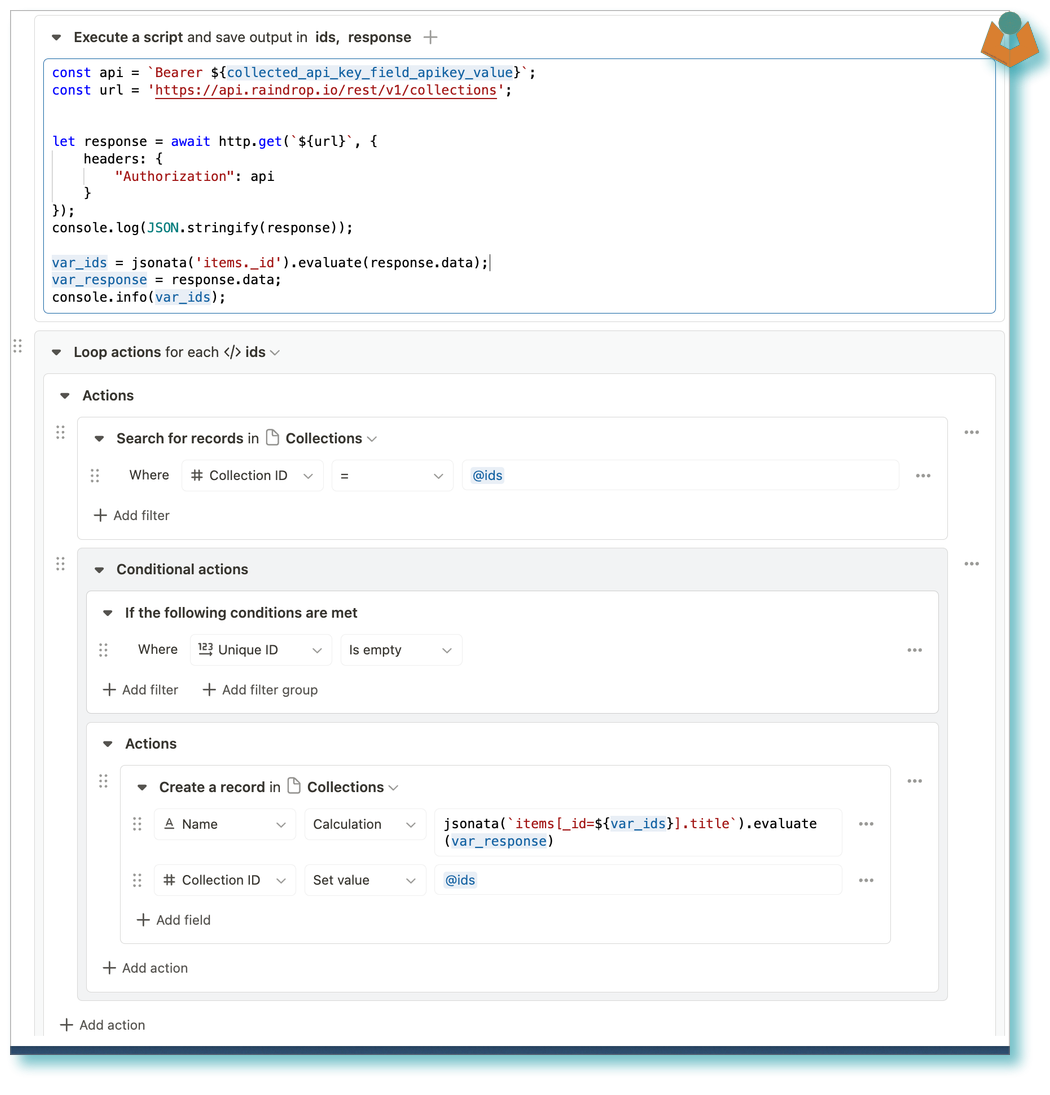
It is worth noting that when I started this process I was purely interested in utilising Tape as an API interface to sort my Bookmarks in Raindrops however by this stage I had moved to keeping Raindrops and Tape linked and using Tape as a form of backup system so changes in Raindrops were reflected in Tape.
Allocating containers
This stage was going to take a good few calls to the AI as the only way of doing it that I could see at the time was to deal with one URL at a time to keep it as gentle as possible I ran an interval workflow that processed 12 URLs at a time,
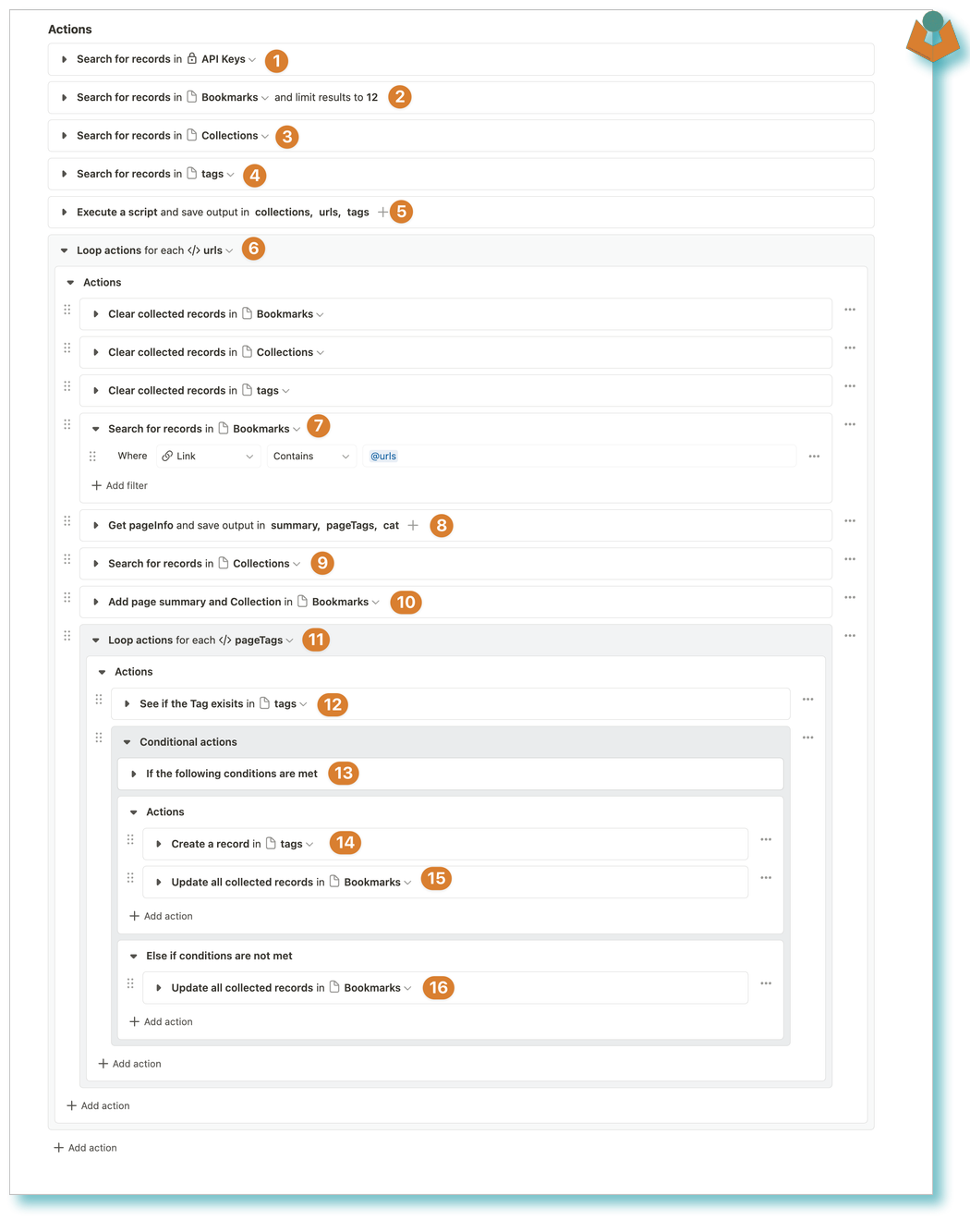
- We get our Perplexity API Key
- We collect our 12 URLs
- Gets all our collections
- Gets a list of tags
- Here we build an array for our Raindrop collections, the Tags and the URLs:
- We use the array of URLs and loop through each
- We search for the specific URL in our Bookmarks so we have a record to update
- We make a call to Perplexity with the URL, the Raindrop collections and the Tags list and ask it to allocate the page to a collection, give the page Tags and finally provide us with a page summary
- We search for the collection
- We add the summary and the collection to our Bookmark record
- We loop through each Tag that was provided by Perplexity
- We search the Tags app for the tag
- A check to see if the Tag exists or not
- Create the Tag in the Tags app if it doesn’t exist
- Add the Tag to our Bookmark
- If the Tag already exists then add it to the bookmark record
The code for stage five:
var_collections = jsonata('fields[field_id=358044].values.value').evaluate(record_collection_collections;
var_urls = jsonata('fields.values.url').evaluate(record_collection_bookmarks_38208;
var_tags = jsonata('fields[field_id=358024].values.value').evaluate(record_collection_tags_38210;
The code for stage 8:
const api = collected_api_key_field_apikey_value;
const { data: openapi_response } = await http.post(
'https://api.perplexity.ai/chat/completions',
{
headers: {
"Content-Type": "application/json",
"accept": "application/json",
"Authorization": `Bearer ${api}`
},
data: {
"model": "llama-3-sonar-large-32k-online",
"messages": [
{
"role": "system",
"content": `Your response must be a valid JSON object and only that do not add any additional text before or after the JSON.`
}
{
"role": "user",
"content": `You are going to be given a URL <url>${collected_bookmark_field_link_url}</url> a categories list and also a list of tags. I need you to examine the contents of the URLs page and do the following:
1. You should allocate the page one of the categories that you have been given.
2. You should allocate any of the tags that you have been provided, if you need additional tags for full categorgrisation the list new ones but keep in mind that too many tags will be counter productive.
3. The final step is I would like you to provide a summary of the page.
Your response should be a valid JSON Object with the keys: "category", "tags", "summary" the tags list should be an array, this JSON object is all that should be included in your response. The lists now follow:
<catrgories>${var_collections}</catergories>
<tags>${var_tags}</tags>`
}
],
"temperature": 0.7
}
}
);
if (openapi_response.error) {
throw new Error(openapi_response.error.message)
}
let content = openapi_response?.choices[0]?.message?.content;
console.log('content', content)
// Remove leading "```json\n" if present
if (content.startsWith("```json\n")) {
content = content.substring(8); // Remove the first 8 characters
}
// Remove trailing "```" if present
if (content.endsWith("```")) {
content = content.substring(0, content.length - 3); // Remove the last 3 characters
}
content = JSON.parse(content);
// console.log('content', content);
var_cat = jsonata('category').evaluate(content);
var_pagetags = jsonata('tags').evaluate(content);
var_summary = jsonata('summary').evaluate(content);
console.info('cat', var_cat);
console.info('Page Tags', var_pagetags);
console.info('Summary', var_summary);
NOTE: This is the first time we have gained any summary, or webpage content until now we have only been working with the URL of a page.
Upload to Raindrops
Now that we have our URLs all allocated a collection we are going to upload them to Raindrops. Raindrops has a Batch upload facility however again I met an issue with Tape’s restrictions which meant I had to split my batches further and i used this workflow:
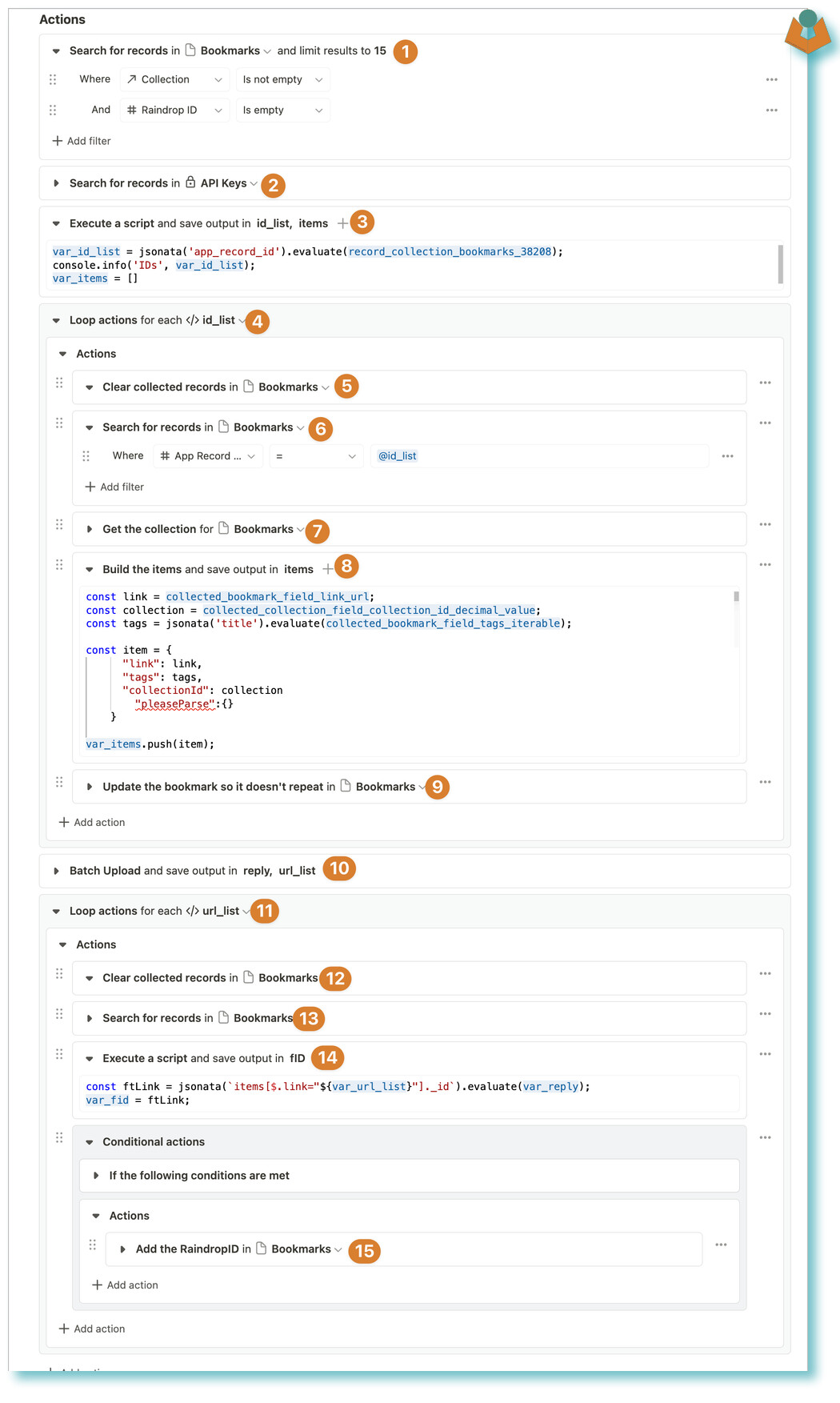
I think most of this workflow is self-explanatory however in case it is not:
- Search for bookmarks that have been allocated a ‘Collection’ but have as yet not got a Raindrops ID
- Get the Raindrops API Key
- Build an Array of Record IDs and also make a blank array
- We can now loop through our IDs
- We clear our workflow collection of Bookmarks
- Search for the bookmark that has the corresponding ID to our loop item
- We get the Raindrop collection details from the related record
- we now build the ‘Items’ Array to send to Bookmarks
- Add a marker to the bookmark record
- Our batch upload call - we then build a list of URLs that have been processed from the response
- Looping through the URL list
- Again clear the bookmarks just to be safe
- Search for the bookmark record with the corresponding URL
- I extract the Raindrops ID from the response
- I added the ID to the bookmark record - 14 and 15 could have been done in one step
Conclusion
I now have a nice collection of bookmarks organised in a consistent manner. What this shows is how easy it is to effectively use Tape to pull data from different sources and pass them onto AI agents then take those responses and pass them into different systems, applications or back into other agents for further processing.
As I have decided to keep my Tape ‘backup’ of Raindrops I have since added a stage that goes and gets a Markdown copy of every web page and adds it to the bookmark record.
